Documentation Index
Fetch the complete documentation index at: https://firecrawl.sec-lab.cn/llms.txt
Use this file to discover all available pages before exploring further.
为 Dify 工作流同步网站数据
Firecrawl 可以在 Dify LLM 工作流构建器 内部使用。本页介绍如何从网页抓取数据,将其解析为 Markdown,并使用 Firecrawl 集成将其导入到 Dify 知识库中。配置 Firecrawl
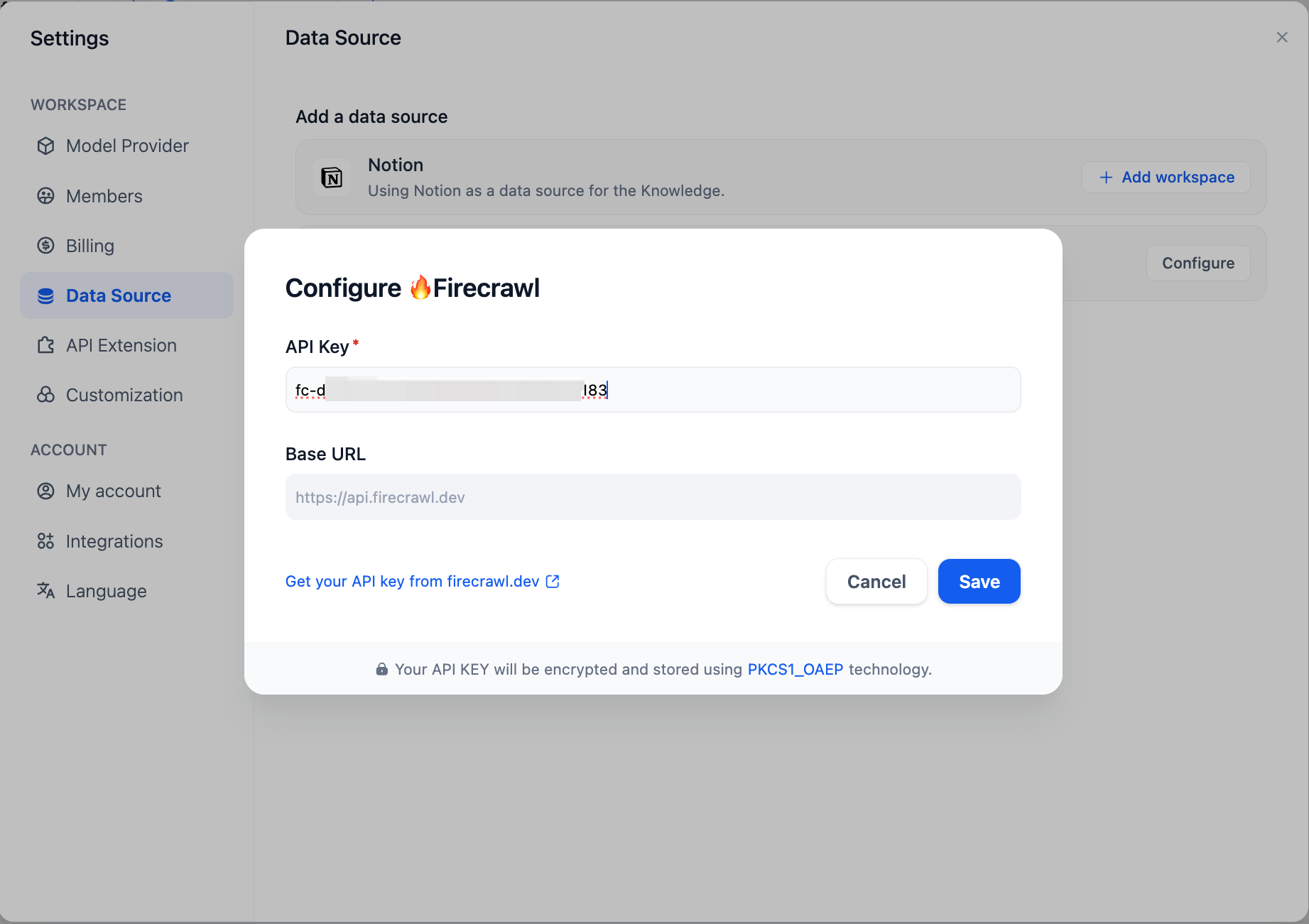
首先,您需要在设置页面的数据源部分配置 Firecrawl 凭据。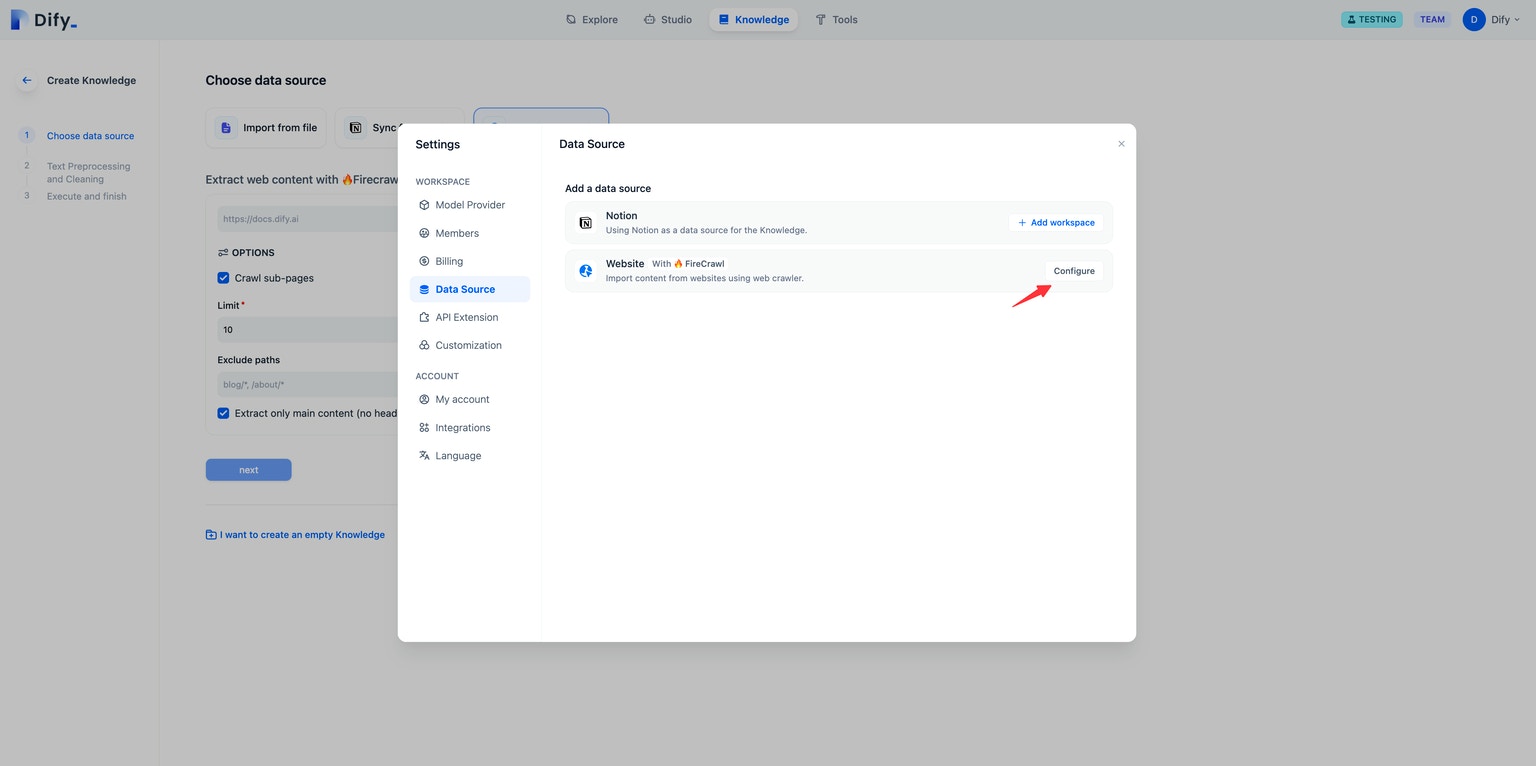
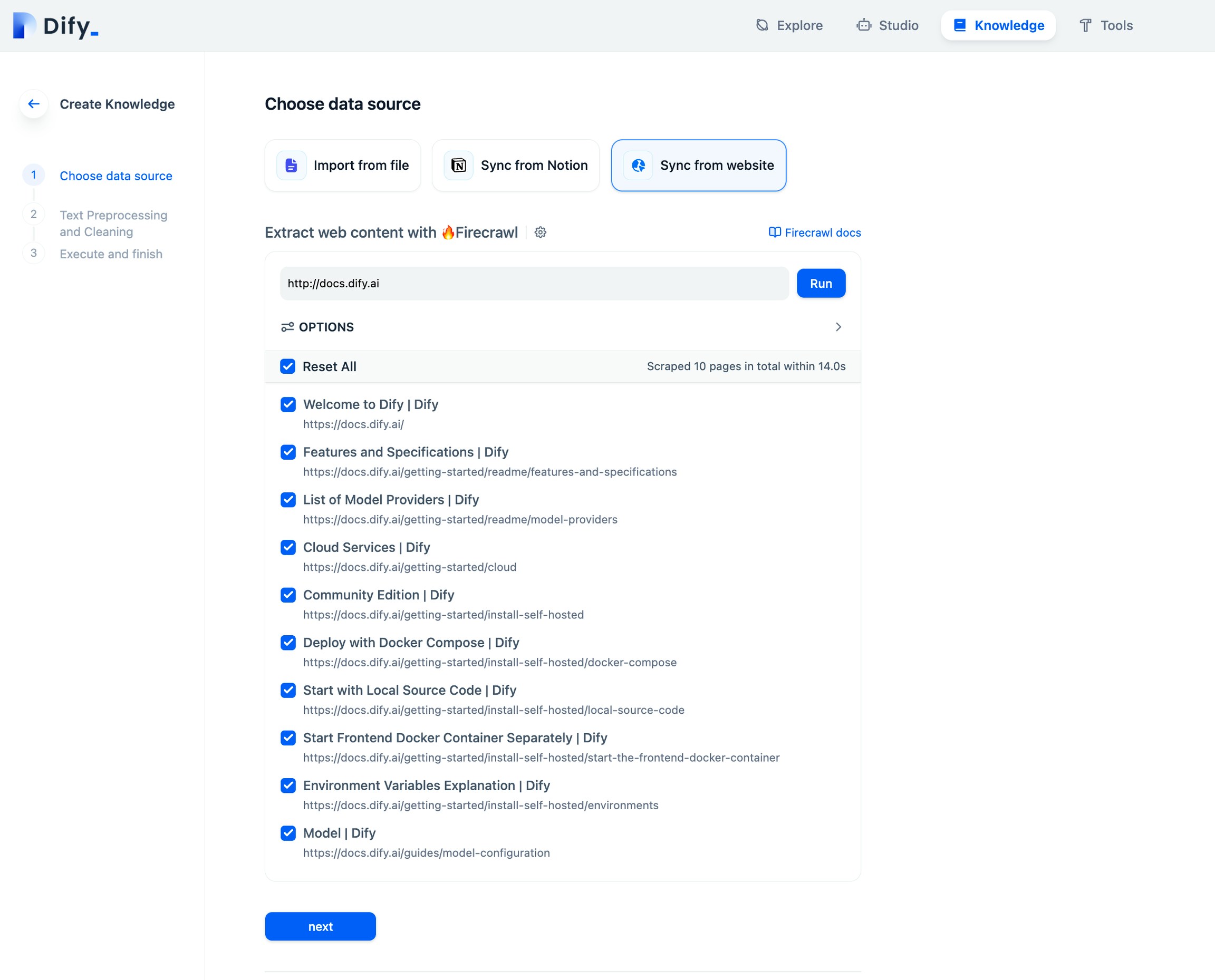
抓取目标网页
现在是有趣的部分,抓取和爬取。在知识库创建页面上,选择从网站同步并输入要抓取的 URL。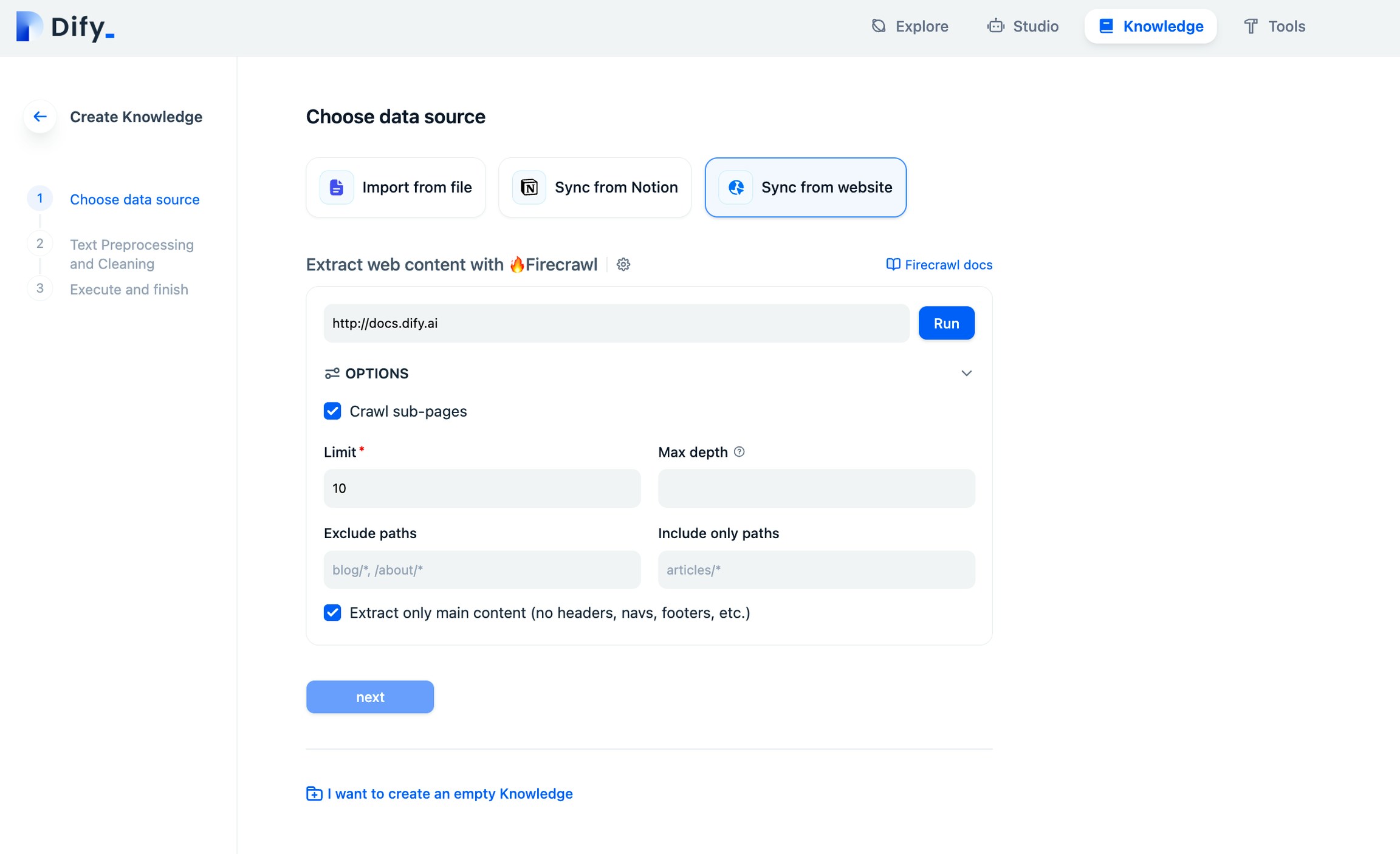
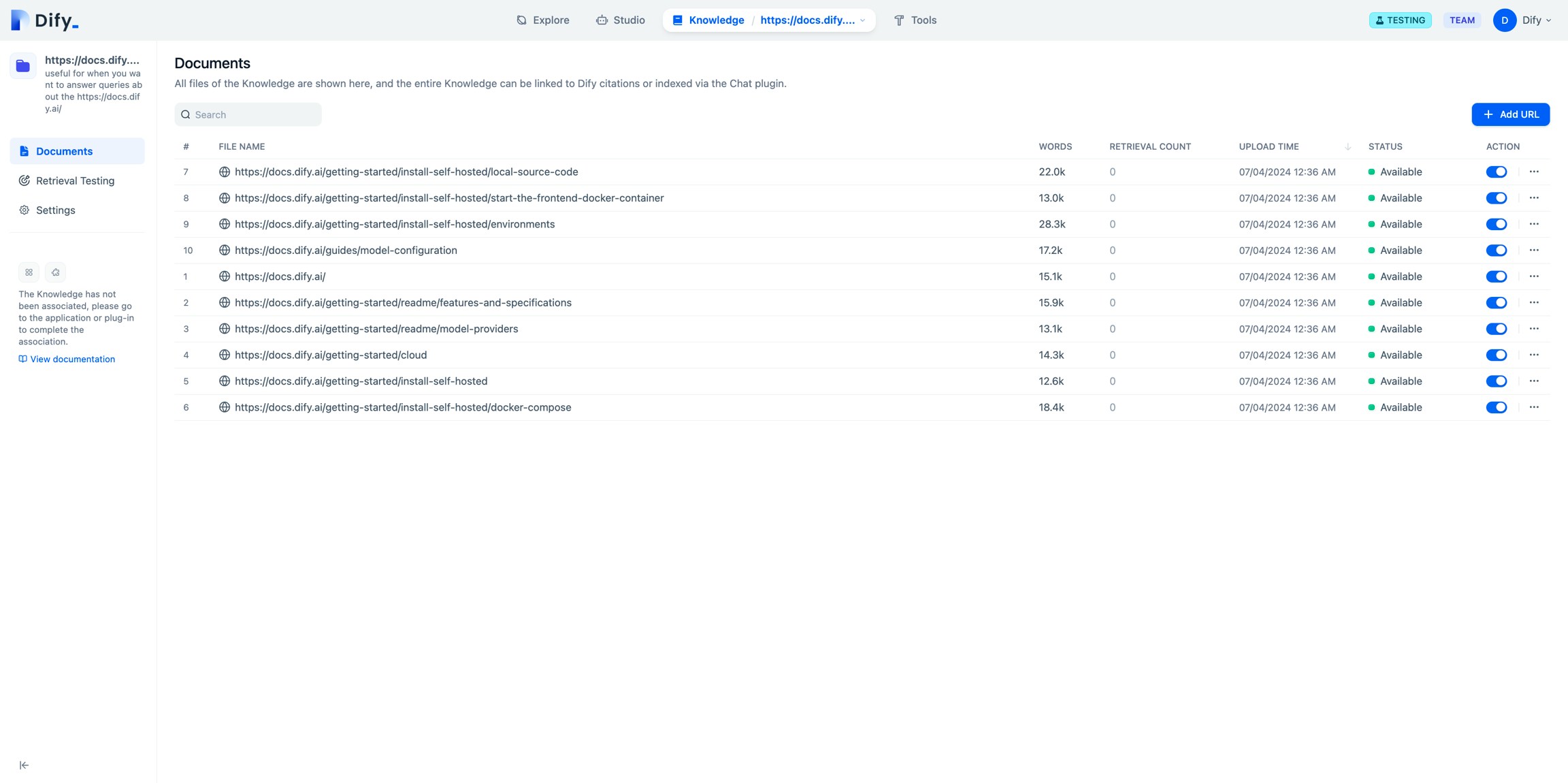
查看导入结果
从网页导入解析的文本后,它会存储在知识库文档中。查看导入结果并点击添加 URL 继续导入新的网页。