Documentation Index
Fetch the complete documentation index at: https://firecrawl.sec-lab.cn/llms.txt
Use this file to discover all available pages before exploring further.

欢迎使用 Firecrawl
Firecrawl 是一个 API 服务,它接收 URL,爬取内容,并将其转换为干净的 markdown 格式。我们会爬取所有可访问的子页面,并为每个页面提供干净的 markdown。无需站点地图。如何使用?
我们提供了一个易于使用的 API 和托管版本。您可以在这里找到 playground 和文档。您也可以自行托管后端。 查看以下资源开始使用:- API:文档
- SDK:Python、Node、Go、Rust
- LLM 框架:Langchain (python)、Langchain (js)、Llama Index、Crew.ai、Composio、PraisonAI、Superinterface、Vectorize
- 低代码框架:Dify、Langflow、Flowise AI、Cargo、Pipedream
- 其他:Zapier、Pabbly Connect
- 需要 SDK 或集成?请通过提交 issue 告诉我们。
API 密钥
要使用 API,您需要在 Firecrawl 上注册并获取 API 密钥。功能
- 抓取:抓取 URL 并获取 LLM 可用格式的内容(markdown、通过 LLM Extract 获取结构化数据、截图、HTML)
- 爬取:抓取网页上的所有 URL 并以 LLM 可用格式返回内容
- 映射:输入网站并获取所有网站 URL - 速度极快
强大的功能
- LLM 可用格式:markdown、结构化数据、截图、HTML、链接、元数据
- 处理困难任务:代理、反机器人机制、动态内容(js 渲染)、输出解析、编排
- 可定制性:排除标签、使用自定义头信息爬取需要认证的网站、最大爬取深度等…
- 媒体解析:PDF、docx、图像
- 可靠性优先:设计用于获取您需要的数据 - 无论多么困难
- 操作:在提取数据前进行点击、滚动、输入、等待等操作
爬取
用于爬取 URL 及其所有可访问的子页面。这会提交一个爬取任务并返回一个任务 ID,用于检查爬取状态。安装
使用方法
async crawl 函数,这将返回一个 ID,您可以用它来检查爬取状态。
检查爬取任务
用于检查爬取任务的状态并获取其结果。响应
响应将根据爬取状态而有所不同。对于未完成或超过 10MB 的大型响应,将提供next URL 参数。您必须请求此 URL 以检索下一个 10MB 的数据。如果 next 参数不存在,则表示爬取数据已结束。
抓取
要抓取单个 URL,请使用scrape_url 方法。它接受 URL 作为参数,并以字典形式返回抓取的数据。
响应
SDK 将直接返回数据对象。cURL 将返回与下面完全相同的负载。提取
通过 LLM 提取,您可以轻松地从任何 URL 中提取结构化数据。我们还支持 pydantic 模式,使其更易于使用。以下是使用方法: v1 目前仅支持 node、python 和 cURL。JSON
无模式提取(新功能)
现在您可以通过仅向端点传递prompt 来进行无模式提取。LLM 会自行选择数据结构。
JSON
提取 (v0)
通过操作与页面交互
Firecrawl 允许您在抓取网页内容之前执行各种操作。这对于与动态内容交互、在页面间导航或访问需要用户交互的内容特别有用。 以下是一个使用操作导航到 google.com,搜索 Firecrawl,点击第一个结果并截图的示例。 在执行其他操作前后使用wait 操作几乎总是很重要的,这可以给页面足够的加载时间。
示例
输出
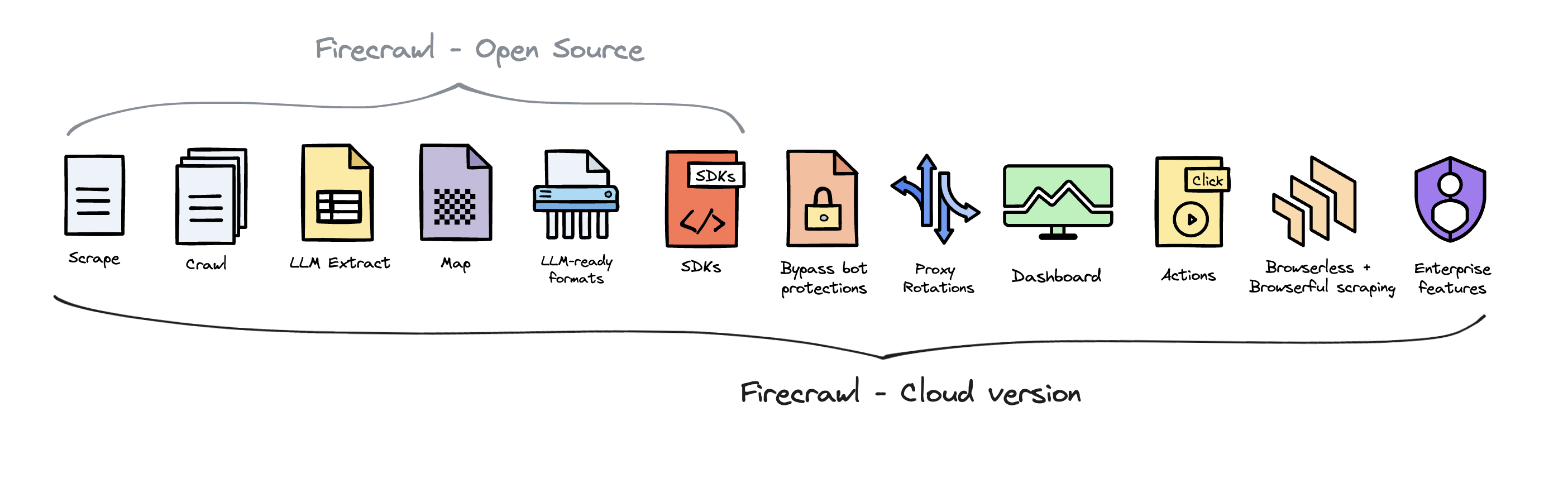
开源版与云版
Firecrawl 是开源的,使用 AGPL-3.0 许可证。 为了提供最好的产品,我们在开源版本的基础上提供了 Firecrawl 的托管版本。云解决方案使我们能够不断创新并为所有用户维护高质量、可持续的服务。 Firecrawl Cloud 可在 firecrawl.dev 获取,并提供开源版本中不可用的一系列功能: